Our funding comes from our readers, and we may earn a commission if you make a purchase through the links on our website.
How to Protect Data at Rest

UPDATED: September 23, 2022
The most popular ways to protect data at rest are through encryption and access control, but still, there are other practices and technologies that you can use to ensure data at rest is not exposed to the risk of unauthorized access.
In this post, we’ll go through eight different ways to protect data at rest (including data access control and encryption). To protect this type of data, you can start by identifying and classifying data, then controlling access, enforcing encryption (or tokenizing your data), physical security, backup, endpoint management, and using a DLP tool.
Why Protect Data at Rest?
Data at rest is a state of data, regardless of its sensitivity, where data is statically stored on a non-volatile storage medium, including block and object storage, databases, archives, IoT devices, etc. This type of data is barely accessed or modified (i.e., only for the duration of a workload), and for most companies, it possesses a great value.
Data at rest is usually located within the limits of an organization and is protected by the cybersecurity strategy. Although this type of data is usually less vulnerable to attacks and threats (as compared to data in transit), it still possesses a high-security risk. The main reason is that data at rest has a higher value for hackers and attackers— if they manage to steal it, they would usually take a much larger volume of valuable data than the few bits of information they would take from the data in transit.
An outsider with bad intentions would target data at rest by using techniques like physical theft, Malware, brute force, phishing, social engineering, etc. For instance, leaving a malware-infected USB in the organization’s parking lot, trying phishing scams, or attacking by brute force. But threats are also internal. Insider threats are often accidental, for instance, a careless employee that leaves his laptop unlocked in a public place or an employee’s endpoint that is stolen. Either way, the data at rest could be accessed using a USB flash drive (for boot) or by hacking the login credentials. There are also bad intentional attacks on data, especially from disgruntled employees who will steal or tamper with data.
Regulations and Compliance
Regardless of where a company is located, if it is digital, it is likely to be handling data that belongs to someone else in some way. Protecting a company’s (including that of employees, customers, etc.) sensitive data is no longer simply a necessity but is most often mandatory. Another big reason to protect data is to comply with strict regulations and industry standards.
Data protection legislation such as Europe’s General Data Protection Regulation (GDPR) or the California Consumer Privacy Act (CCPA) makes companies responsible in front of the law for protecting sensitive data, including Personally Identifiable Information (PII) and Intellectual Property (IP) of customers as well as employees.
In addition, other specialized industry standard laws include HIPAA, which protects healthcare data; PCI DSS, which governs credit card information; and SOX, which deals with financial reporting. Failure to comply with such standards and regulations will lead the company to expensive fines and will also be prohibited from participating in bids. All such roads lead to losing the business.
Best Practices on How to Protect Data at Rest
Data at rest is usually best protected with encryption and access controls, but there are also some other practices and tools that must be considered to protect data at rest.
1. Identify and classify sensitive data
To protect data efficiently, you’ll first need to know precisely what type of data you have and how sensible it is. Knowing what you have in store can help you create better access controls later. You’ll know which critical data to store in a different location, which one to enforce encryption on, and which data to give access to which user.
Data discovery technologies can help you scan the data at rest at repositories and create detailed reports. Once data has been identified, you can use the same tools and technologies to classify the data into different categories and encrypt, delete or move hard-to-find sensitive data.
Disadvantage: Data can be accidentally (or intentionally) mislabeled. A data admin can accidentally mislabel data and put the “sensitive data” into a different “less-sensitive” category. A bad-intentioned insider can also falsify the classification level and downgrade the sensitivity of data to access it externally.
2. Control and manage data access
To protect data at rest, you'll need to control who has access to which data and what level of access (read-write-execute) they have to that data. It is vital to ensure that the appropriate user (employee, customer, or contractor) has access to just the data they need without exposing unnecessary need-to-know data. The best approach to consider when controlling data access is to take the “deny all permit what's needed” approach to reduce any sort of exposure.
After data has been classified (as seen in the previous section), you'll need to create access control policies. These policies determine the permitted activities of users for specific resources; they help you control the conditions for data access based on the classification— who has access to the data, what the user can do with it, etc.
Access control systems (and policies) use various methods, such as enforcing authentication via solid passwords and using optional “stronger” mechanisms such as 2FA (Two-way Factor Authentication), OTP (One Time Passwords), or biometric readers.
Limitations: Data access control systems aim to restrict access and prevent theft. But the added level of security may also compromise the user's usability. For example, users forget their tokens or devices; they write their changing passwords on paper; They also have more challenges accessing their data, especially when traveling.
3. Encryption is king
Encryption is one of the best solutions to protect data at rest. It makes data unreadable to anyone who gets their hands on it, except those with the appropriate key or password. Aside from encrypting only sensitive data, organizations may also choose to encrypt the entire storage drive.
There are many types of encryption mechanisms, some stronger than others. When you want to protect data at rest, it is vital to use strong data encryption mechanisms like the AES (Advanced Encryption Standard), BlowFish, or Triple DES.
As a best practice, always ensure that the only way to store data is if data is encrypted. This can be done through an endpoint encryption software solution that provides strong encryption mechanisms, enforces encryption, allows key management, and supports various OSs.
Limitations: Although it would seem that encryption is the cure to all, it does have a few flaws. One of the most significant is key management. The more data encryption keys there are, the more difficult it is to manage them. If a key is lost, the data is gone forever. Another disadvantage of robust, highly secure encryption is that it compromises processing performance. The more encryption is used, the more processing overhead is introduced.
4. Tokenize your sensitive data
Tokenization is another great way to protect data-at-rest. Data at rest that is encrypted is usually not tokenized. Organizations with solid cybersecurity strategies usually do one or the other (encryption or tokenization), but not both.
Tokenization is a process that replaces sensitive data with unique identification symbols. Such symbols retain all the important information about the data without compromising security. A token, for instance, may represent a credit card number, a social security number, or an address. Tokens by themselves are meaningless, as the data (that is being tokenized) is not stored or sent in its real form.
Tokens provide additional protection for your sensitive data and help ensure compliance requirements. Tokens have become popular in industries wanting to improve the security of credit card or online transactions while also reducing compliance and regulations complexities. Tokens are especially popular in the Payment Card Industry Data Security Standard (PCI-DSS).
Disadvantage: One of the most common disadvantages of tokenization is its lack of scalability. Tokens are fit for small to medium organizations. Larger organizations are unable to use tokenization to address all their data. In addition, tokenization is not widely supported by different applications and technologies.
5. Physical security
Physical security is one of the most obvious but often underrated ways to protect data at rest. A physically-secured and monitored perimeter to safeguard data can be critical to avoiding data theft, loss, or tampering.
If your servers storing data at rest are well protected by solid doors, biometric authentication, security guards, video surveillance, remote monitoring, network segmentation (and even safe from natural disasters,) then it is likely that no hacker (or unauthorized outsider) could simply approach them and steal their data. Some companies take it to the extreme by air gapping (isolating a computer or network from an external connection) to ensure that data-at-rest is completely safe.
In addition, physical security also entails teaching remote employees to protect their devices, mobiles, or even physical papers from falling into the wrong hands. Employees should never leave their devices unattended in public places and always lock them.
Limitations: Physical security can do little about insider threats and much less about open and weak network security. If channels like email or cloud apps leak data, then strong physical security is redundant.
6. Back up, back up, back up
Data at rest is simply data stored in a hard drive, cloud, database, external media, etc. Although a backup by itself could also be considered data-at-rest, it is always a good practice to perform backups of data-at-rest to protect it. Words like data redundancy or fault tolerance are improved through data backups.
Back up your data-at-rest using the 3-2-1 rule. (3) Create one primary backup along with two copies of the data. (2) Store your backups in two different types of media (i.e., external drive and cloud), and (1) always keep at least one copy of the backup file offsite. Although an offsite backup could be performed on the same network, it is always recommended to back up to remote storage (i.e., cloud or dedicated physical server). In addition, always consider encrypting your backups.
Limitations: The amount of data that can be saved offsite (to a cloud server) each day is strongly limited by the bandwidth. Daily large offsite backups from a client with low bandwidth are highly unreliable. Another main concern to keep in mind is that ransomware campaigns are now targeting backups. Having data encrypted by ransomware can always be solved by a backup and restore, but having the data backup targeted by ransomware does not have a solution.
7. Manage Endpoints
An endpoint is simply the end of a communication channel. It is usually a remote computing device that communicates with a specific network. Endpoints have the largest attack surface, so they are constantly prone to attacks.
By knowing which endpoints connect to your resources and having a way to manage them, you can protect them while also protecting the data inside them. Endpoint protection entails following usual cybersecurity best practices, including using (and updating) anti-virus, patching software, shutting down inactive sessions, enforcing strong passwords (and device passcodes), enabling firewall, and more.
Challenges: Critical data at rest may leave the endpoint (through cloud apps, email, etc.) at any time. Overseeing the inbound and outbound data flows to endpoints outside the network, such as mobiles, IoT devices, remote workers, and Bring Your Own Device (BYODs), can be pretty challenging to manage and control.
8. Use a Data Loss Prevention Tool
One of the best ways to protect data at rest is by using a Data Loss Prevention (DLP) solution. A DLP ensures that a company’s sensitive data is not stolen, lost, misused, or accessed by an unauthorized user. Modern DLP tools usually protect data from leaking out via different channels, including cloud, email, third-party apps, on-prem networks, endpoints, and more. These are great options to deal with data leaking from endpoints (as mentioned in the previous section), such as mobiles, IoT, and BYOD policies.
An endpoint protection solution
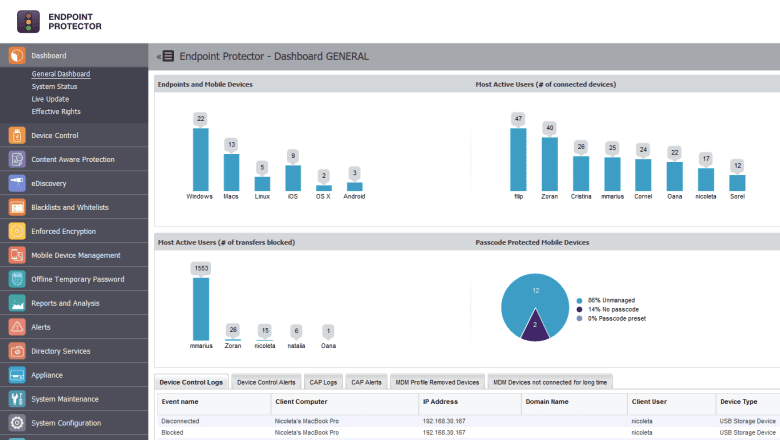
One of the best ways to avoid data breaches is to use endpoint security systems, such as the CoSoSys Endpoint Protector. This endpoint protection solution can scan data at rest, discover, encrypt, or delete sensitive data. Additionally, this solution can also monitor, scan, and block data in transit.
A DLP solution such as CoSoSys Endpoint Protector also provides device control. It can help admins block (or limit) the usage of USB, removable devices, external hard drives, etc. It can also allow specific “approved” USB devices (based on hardware) but “automatically” enforce encryption to all copied files.
Final Words
To protect data at rest, the two most essential practices are encryption and data access controls. Other practices and technologies that can also improve the security of your data at rest are data discovery and classification (to find sensitive data) and encryption or tokenization to ensure that data is protected if it falls into the wrong hands. Other ways to protect data at rest are physical security, backing up your data, managing your endpoints, and using a Data Loss Prevention tool.